1 简介
ZREVRANGEBYSCORE 返回有序集合中指定分数区间内的成员,分数由高到低排序。
2 语法
2.1 完整示例
1
| ZREVRANGEBYSCORE key max min WITHSCORES LIMIT offset count
|
2.2 说明
| 指令 |
是否必须 |
说明 |
| ZREVRANGEBYSCORE |
是 |
指令 |
| key |
是 |
有序集合键名称 |
| max |
是 |
最大分数值,可使用”+inf”代替 |
| min |
是 |
最小分数值,可使用”-inf”代替 |
| WITHSCORES |
否 |
将成员分数一并返回 |
| LIMIT |
否 |
返回结果是否分页,指令中包含LIMIT后offset、count必须输入 |
| offset |
否 |
返回结果起始位置 |
| count |
否 |
返回结果数量 |
提示:
- “max” 和 “min”参数前可以加 “(“ 符号作为开头表示小于, “(“ 符号与成员之间不能有空格
- 可以使用 “+inf” 和 “-inf” 表示得分最大值和最小值
- “max” 和 “min” 不能反, “max” 放后面 “min”放前面会导致返回结果为空
- 计算成员之间的成员数量不加 “(“ 符号时,参数 “min” 和 “max” 的位置也计算在内。
- ZREVRANGEBYSCORE集合中按得分从高到底排序,所以”max”在前面,”min”在后面, ZRANGEBYSCORE集合中按得分从底到高排序,所以”min”在前面,”max”在后面。
3 返回值
指定分数范围的元素列表。
4 示例
4.1 按分数倒序返回成员
“+inf” 或者 “-inf” 来表示记录中最大值和最小值。
“(“ 左括号来表示小于某个值。目前只支持小于操作的 “(“ 左括号, 右括号(大于)目前还不能支持。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
| redis> ZADD myzset 1 "one" (integer) 1 redis> ZADD myzset 2 "two" (integer) 1 redis> ZADD myzset 3 "three" (integer) 1 redis> ZREVRANGEBYSCORE myzset +inf -inf 1) "three" 2) "two" 3) "one" redis> ZREVRANGEBYSCORE myzset 2 1 1) "two" 2) "one" redis> ZREVRANGEBYSCORE myzset 2 (1 1) "two" redis> ZREVRANGEBYSCORE myzset (2 (1 (empty list or set) redis>
|
4.2 按分数倒序返回成员以及分数
ZREVRANGEBYSCORE 指令中, 还可以使用WITHSCORES 关键字来要求返回成员列表以及分数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
| redis> ZADD myzset 1 "one" (integer) 1 redis> ZADD myzset 2 "two" (integer) 1 redis> ZADD myzset 3 "three" (integer) 1 redis> ZREVRANGEBYSCORE myzset +inf -inf WITHSCORES 1) "three" 2) "3" 3) "two" 4) "2" 5) "three" 6) "1" redis> ZREVRANGEBYSCORE myzset 2 1 WITHSCORES 1) "two" 2) "2" 3) "one" 4) "1" redis> ZREVRANGEBYSCORE myzset 2 (1 1) "two" redis> ZREVRANGEBYSCORE myzset (2 (1 (empty list or set) redis>
|
4.3 分页返回数据
可以通过 LIMIT 对满足条件的成员列表进行分页。一般会配合 “+inf” 或者 “-inf” 来表示最大值和最小值。
下面的例子中就是使用分页参数返回数据的例子。
1 2 3 4 5 6 7 8 9 10 11 12
| redis> ZADD myzset 1 "one" (integer) 1 redis> ZADD myzset 2 "two" (integer) 1 redis> ZADD myzset 3 "three" (integer) 1 redis> ZREVRANGEBYSCORE myzset +inf (2 WITHSCORES LIMIT 0 1 1) "three" 2) "3" redis> ZREVRANGEBYSCORE myzset +inf (2 WITHSCORES LIMIT 2 3 (empty list or set) redis>
|
5 应用
5.1 时事新闻
我们的网易新闻、腾讯新闻、一点资讯、虎嗅、快科技等新闻类应用场景中, 新闻会根据时间排列,形成一个队列,
在这些网站浏览新闻时, 每次刷新页面都能获取到最新的数据,当然还可以通过分页查看历史数据,
但每次刷新首页都将是一个以最新数据为基础进行分页。
这又区别于面前今日头条的下拉刷新机制,关于今日头条的下拉刷新机制我们下节讲,这一节先讲讲如何实现新闻资讯队列分页。
场景及需求:
根据数据类型分频道来展示资讯,比如时事新闻,根据时间排序,用户进入网站就获取到最新时事新闻,后台能实时向时事新闻频道增加新闻,且只要用户刷新就能看到最新的时事新闻,然后以最新新闻为基础进行分页展示。
我们根据时间添加5条新闻到news频道。
1 2 3 4 5 6 7 8 9
| redis> zadd news 201610022301 '{"title" : "new1", "time": 201610022301}' (integer) 1 redis> zadd news 201610022302 '{"title" : "new2", "time": 201610022302}' (integer) 1 redis> zadd news 201610022303 '{"title" : "new3", "time": 201610022303}' (integer) 1 redis> zadd news 201610022304 '{"title" : "new4", "time": 201610022304}' (integer) 1 redis> zadd news 201610022305 '{"title" : "new5", "time": 201610022305}'
|
实际场景中new1、news2…等等都应该是一个json对象,包含新闻标题、时间、作者、类型、图片URL…等等信息。
然后当用户请求新闻时,我们会使用这个命令查询出最新几条记录:
1 2 3
| redis> ZREVRANGEBYSCORE news +inf -inf LIMIT 0 2 1) "{\"title\" : \"new5\", \"time\": 201610022305}" 2) "{\"title\" : \"new4\", \"time\": 201610022304}"
|
上面的例子中,我们从news频道查询出来了2条最新记录。如果用户翻页,我们会使用最新记录中时间最大的记录做为参数进行分页。依次查询第二页,第三页。
1 2 3 4 5 6
| redis> ZREVRANGEBYSCORE news 201610022305 -inf LIMIT 2 2 1) "{\"title\" : \"new3\", \"time\": 201610022303}" 2) "{\"title\" : \"new2\", \"time\": 201610022302}" redis> ZREVRANGEBYSCORE news 201610022305 -inf LIMIT 4 2 1) "{\"title\" : \"new1\", \"time\": 201610022301}" redis>
|
总结: 我这里没有使用当前时间作为最大值查询,是为了避免用户电脑时间不准确导致请求失败。比如刚装系统,或者BOIS电池没有电,不能存储系统当前时间,就会导致系统时间都是1970年1月1日,这样,去查询,是查询不到数据的,比如之前的太平洋电脑网,如果你将电脑系统时间改成1970年1月1日,再去访问,就无法获取新数据了。现在有不少网站有类似问题.
在这个业务场景中,如果某个编辑新发布一条新闻到时事新闻中,原来在翻页查看新闻的用户是不受影响的,只有用户刷新浏览器或者刷新首页,就会看到最新的数据了。
5.2 时事新闻下拉更新
上面时事新闻的例子能解决一部分业务场景的需求,但是如果遇到比较较真的产品经理,需要做成类似今日头条下拉刷新最新数据,上拉获取历史记录的功能,那么一个 ZREVRANGEBYSCORE 命令肯定是解决不了问题的。下面我讲讲我一些解决方案的思路。
首先,从队列的角度看需求,以201610022303这个时间为界限,下拉刷新如果获最新数据,就是这样:
1 2 3
| redis> ZREVRANGEBYSCORE news +inf 201610022303 LIMIT 0 2 1) "{\"title\" : \"new5\", \"time\": 201610022305}" 2) "{\"title\" : \"new4\", \"time\": 201610022304}"
|
然后,上拉刷新获取历史数据,分页查询,都没有问题:
1 2 3 4 5 6
| redis> ZREVRANGEBYSCORE news 201610022303 -inf LIMIT 0 2 1) "{\"title\" : \"new3\", \"time\": 201610022303}" 2) "{\"title\" : \"new2\", \"time\": 201610022302}" redis> ZREVRANGEBYSCORE news 201610022303 -inf LIMIT 2 2 1) "{\"title\" : \"new1\", \"time\": 201610022301}" redis>
|
不过,你会发现,下拉刷新时,数据是从最大时间到最小时间排序,如果编辑新增一条数据,就会打乱我们队列的顺序
1 2 3 4 5 6
| redis> zadd news 201610022306 '{"title" : "new6", "time": 201610022306}' (integer) 1 redis> ZREVRANGEBYSCORE news +inf 201610022303 LIMIT 2 2 1) "{\"title\" : \"new4\", \"time\": 201610022304}" 2) "{\"title\" : \"new3\", \"time\": 201610022303}" redis>
|
前一秒,查询第一页数据是news5和news4,我翻页的时候,结果变成了news4和news3,news4重复了。
虽然不会对上拉刷新查询历史数据有影响,但是作为一个实时性非常强的新闻应用,用户更关注的应该是最新的新闻的内容,也就是下拉刷新的功能,如果一个基本的排版都重复,用户的耐心恐怕不会给你更多机会。
想到这,感觉太可怕了!产品经理要是知道,一定会喷死我们的。当然,这不是最要命的问题,最要命的问题是如果用户要是回到第一页(非刷新),就会发现,当初的第一页已经不是刚刚看过的第一页了。
第一页多了一条news6的新闻!
1 2 3
| redis> ZREVRANGEBYSCORE news +inf 201610022303 LIMIT 0 2 1) "{\"title\" : \"new6\", \"time\": 201610022306}" 2) "{\"title\" : \"new5\", \"time\": 201610022305}"
|
还有一个问题,就是如果用户前一天看到第二页,隔天登录,然后请求最新新闻,还会是第二页吗?
可以考虑以下解决思路:
首先,需要前端和后端配合,前端定义三个动作,首次登录,下拉刷新(获取最新数据),上拉刷新(获取历史数据),定义一个下拉刷新时间和一个上拉刷新时间,
如果是首次登录,先判断下拉刷新时间是否比今天凌晨时间小,如果小,证明已经隔天了,将下拉刷新时间设置成当天凌晨时间;
如果下拉刷新时间比今天凌晨时间大,说明用户看过今天新闻,就直接用下拉刷新时间请求新数据。
对于上拉刷新请求数据,可以在判断首次请求时,出现隔天后,将上拉刷新时间置为当天凌晨时间。这样在请求历史数据时,不至于丢失中间的数据。
当然,关键还是命令的使用,查询历史数据时,还可以使用 ZREVRANGEBYSCORE 来获取数据,不过,获取最新数据,就可以使用 ZRANGEBYSCORE 来取数据。
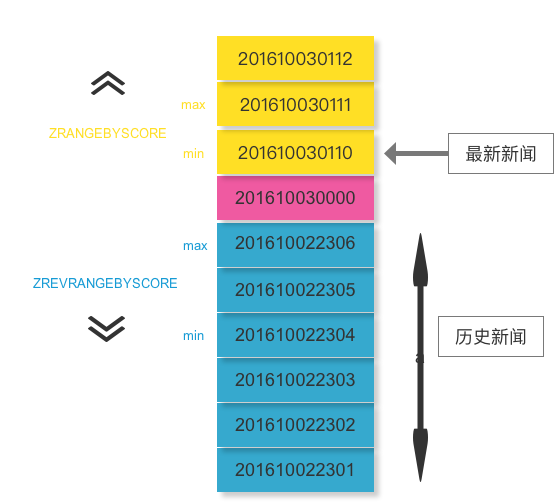
1 2 3 4 5 6 7 8 9 10 11
| redis> zadd news 201610030110 '{"title" : "new7", "time": 201610030110}' (integer) 1 redis> zadd news 201610030111 '{"title" : "new8", "time": 201610030111}' (integer) 1 redis> zadd news 201610030112 '{"title" : "new9", "time": 201610030112}' (integer) 1 redis> ZRANGEBYSCORE news 201610030000 +inf LIMIT 0 2 1) "{\"title\" : \"new7\", \"time\": 201610030110}" 2) "{\"title\" : \"new8\", \"time\": 201610030111}" redis> ZRANGEBYSCORE news 201610030000 +inf LIMIT 2 2 1) "{\"title\" : \"new9\", \"time\": 201610030112}"
|
总结: 时事新闻下拉更新这个例子中, 可以使用每次请求数据的最大时间戳和最小时间戳来作为下一次请求的输入,这里的时间戳的概念不限于时间,可以是数据库里的自增ID,然后在缓存中定义一个当天的ID,每当隔天出现,就取获取这个ID,然后通过这个ID作为当天凌晨的时间戳标记,
获取比这个ID大或者小的结果集来完成获取最新数据和历史数据的功能,这样就可以解决客户端时间不准确后获取不到数据的问题。